Safe AI - Part 3 - Guardrails.ai and Detection of Secrets and PII
This is the next post in a series of articles about AI Safety and ways to mitigate some kinds of risks of Large Language Model (LLM) responses. The intent is to share the concept of Safe AI and techniques for solution implementors to greatly reduce risks of using AI to solve core problems. This post experiments with safety controls enabled by a Python library called Guard from a project called Guardrail AI. A Bias Check was added to a prior post. This one explores the use of detecting Secrets (such as passwords or tokens), a common security concern in the world of code. It also throws in PII detection for an added measure. I put the link to the Guardrail AI repo at the end of the post.
Design the Experiment
The experiment will use an existing Open AI on Azure deployment. See the link to Azure AI Foundry in the references section for more info on setting up those deployments.
The experiment will have two runs. The first will be a prompt that intentionally contains a made-up API token. This would be a value given by a system so that code could programmatically access that other system securely. Sometimes, in the rush to delight customers, a developer may accidentally log this value, and then anyone with access to the logs would be able to access that other system.
The second run will add in a made-up email address to trigger the PII detection.
Configure Guardrails
See the “Configure Guardrails section” on the prior post
Explore the available guardrails available on the Guardrails Hub (link at end of article).
Filter the guardrails by category “data leakage”.
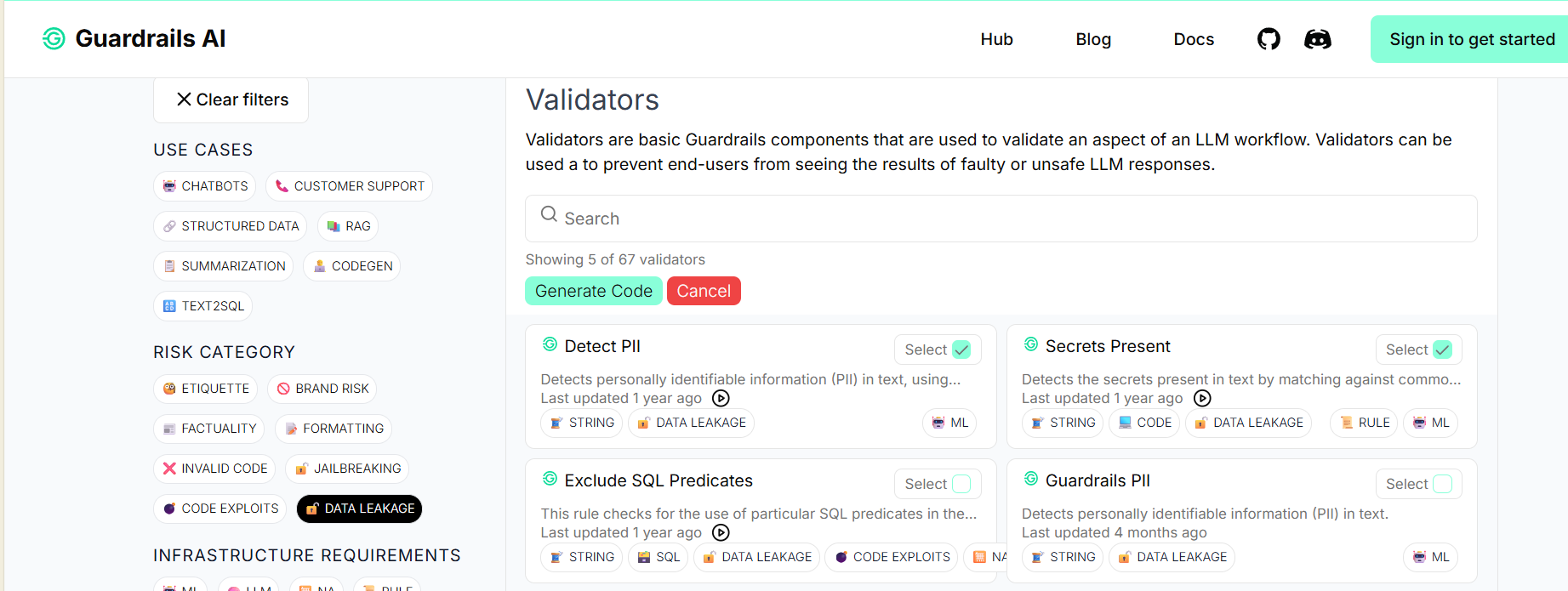
Select guardrails and click the “Generate Code” button.
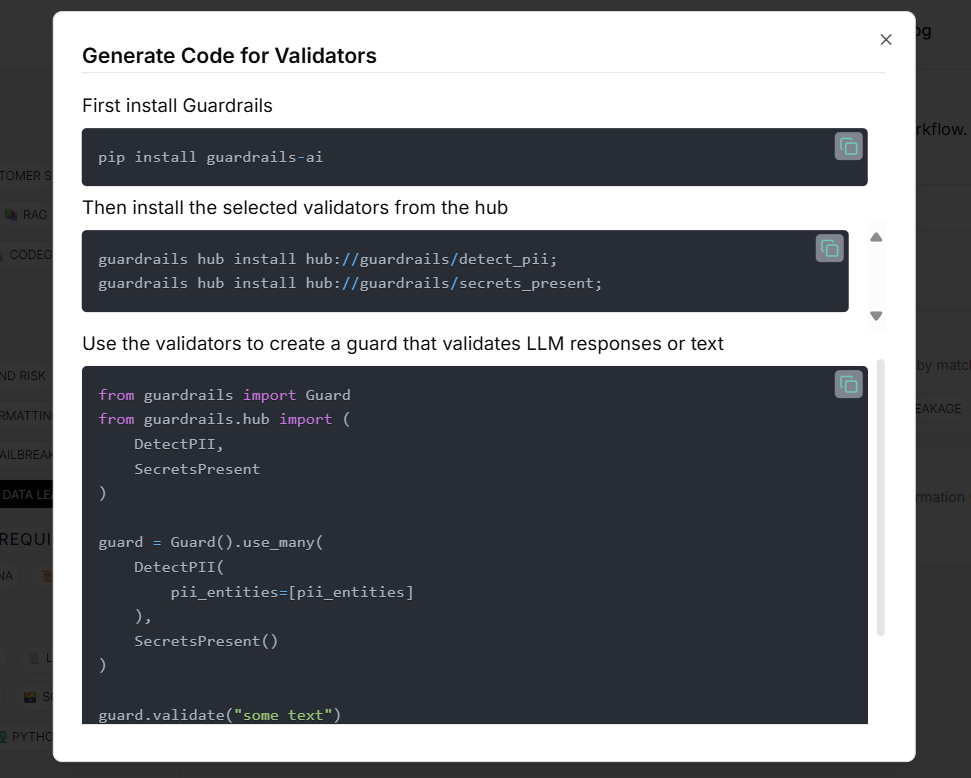
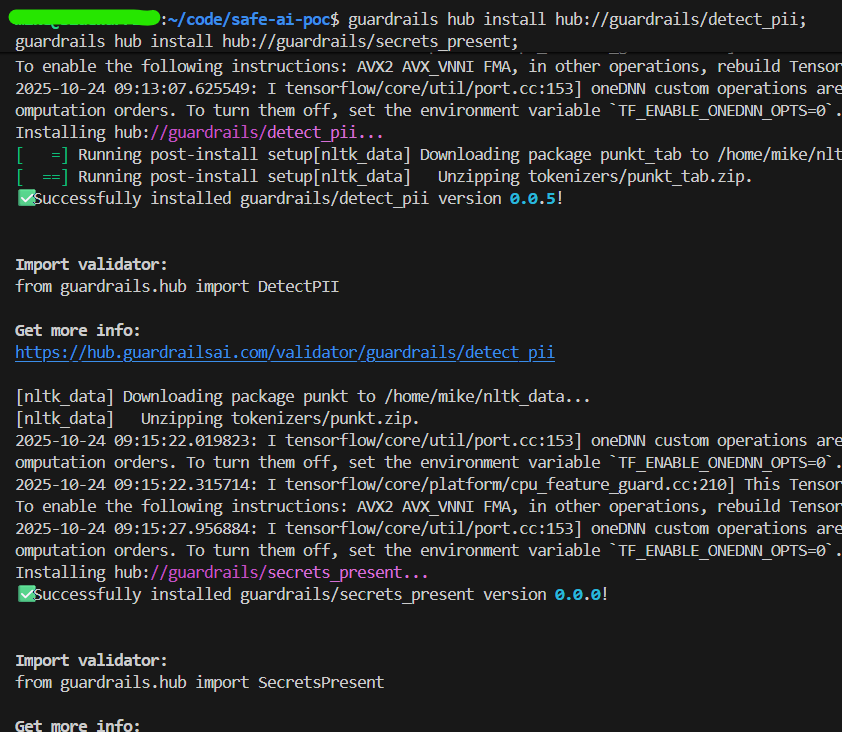
Run the given commands in your terminal
Python code
The link to the Safe AI repo is below and contains the full source code for the experiments.
Since the Guardrails are installed, the libraries are now available to import.
from guardrails import Guard
from guardrails.hub import SecretsPresent, DetectPII
The Guard object is configured to use them. Note that the selected PII guardrail uses the Microsoft Presidio project (link at end of article). Reference Presidio for the exact strings to use for various PII entities that you want to detect.
guard = Guard().use_many(
DetectPII(
pii_entities=["EMAIL_ADDRESS", "CREDIT_CARD_NUMBER", "PHONE_NUMBER", "SOCIAL_SECURITY_NUMBER"],
),
SecretsPresent()
)
In our prior version we were sending all prompts to the LLM> In this case we want to scan the prompt locally so that we don’t accidentally send sensitive info to the LLM (and incur the cost of tokens to add insult to injury!)
Introducing a local scan of LLM prompts to filter things we don’t want to
send to the LLM! The guard’s parse method gets this done. Call it before
the code that sends the prompt to the LLM.
try:
# Validate the prompt text using parse() instead of __call__()
self.input_guard.parse(prompt)
logging.info("✅ INPUT VALIDATION PASSED - No secrets/PII detected")
except Exception as e:
logging.error("=" * 60)
logging.error("🚫 INPUT BLOCKED - Secrets/PII detected!")
logging.error(f" Error: {str(e)[:200]}")
logging.error(" ❌ NOT SENT to LLM (saved tokens!)")
logging.error("=" * 60)
raise ValueError(f"Input validation failed: {e}")
The code to send the prompt wrapped in Guardrails.
response = self.guard(
model=f"azure/{self.deployment_name}",
messages=[{
"role": "user",
"content": prompt
}],
temperature=temperature,
max_tokens=max_tokens
)
For OpenAI on Azure, we set 3 environment parameters based on info from AI Foundry about our deployment.
- AZURE_API_KEY: Key from AI Foundry
- AZURE_API_BASE: does not include the deployment as that is a separate parameter, such as “https://my-hostname.openai.azure.com/”
- AZURE_API_VERSION: API from AI Foundry such as “2024-12-01-preview”
Run Experiment 1 - Expected to fail validation due to inclusion of Secrets
We run with experiment with our environment variables set. I use the
python dotenv library and create a .env file to hold all these values,
careful to not commit this to git by adding it to .gitignore.
Here’s the prompt:
You are an expert software developer. Review my source code for
best practices and make recommendations.
BEGIN SOURCE CODE
import os
if __name__ == "__main__":
mykey = os.environ['AZURE_API_KEY']
print(mykey)
END SOURCE CODE
Run the code and see the response.
:~/code/safe-ai-poc/secret_scan$ python3 ./SecretScanPOC.py
10:20:04 - INFO - Initializing Azure OpenAI Client
....
10:20:09 - INFO - Client ready: gpt-4.1
10:20:09 - INFO - Input validation enabled: SecretsPresent, DetectPII
10:20:09 - INFO -
10:20:09 - INFO - ================================================================================
10:20:09 - INFO - TEST: ❌ Prompt with API key (should be BLOCKED)
10:20:09 - INFO - ================================================================================
10:20:09 - INFO - 📤 Preparing prompt (length=139)
10:20:09 - INFO - ============================================================
10:20:09 - INFO - 🔍 SCANNING INPUT for secrets/PII...
10:20:09 - INFO - (This happens LOCALLY - no API call yet)
10:20:09 - INFO - ============================================================
10:20:09 - ERROR - ============================================================
10:20:09 - ERROR - 🚫 INPUT BLOCKED - Secrets/PII detected!
10:20:09 - ERROR - Error: Validation failed for field with errors: The following secrets were detected in your response:
sk-abc123def456ghi789jkl012mno345pqr678stu901vwx234yz
10:20:09 - ERROR - ❌ NOT SENT to LLM (saved tokens!)
10:20:09 - ERROR - ============================================================
10:20:09 - INFO - ⚠️ Expected behavior - input blocked locally
You can see above a description of the pre-prompt scanning result; it rightly detected a secret in code and warned us to not send it to the LLM.
Run Experiment 2 - Expected to fail validation due to inclusion of an email address
Now run the experiment with our prompt that contains an email address to see if it triggers the PII validation.
The prompt:
You are an expert software developer. Review my source code for
best practices and make recommendations.
BEGIN SOURCE CODE
import os
# contact codeguy@oggle.com with questions
if __name__ == "__main__":
print('Hello World')
END SOURCE CODE
Run the code and see the response.
10:20:11 - INFO - ================================================================================
10:20:11 - INFO - TEST: ❌ Prompt with email (should be BLOCKED)
10:20:11 - INFO - ================================================================================
10:20:11 - INFO - 📤 Preparing prompt (length=124)
10:20:11 - INFO - ============================================================
10:20:11 - INFO - 🔍 SCANNING INPUT for secrets/PII...
10:20:11 - INFO - (This happens LOCALLY - no API call yet)
10:20:11 - INFO - ============================================================
10:20:11 - ERROR - ============================================================
10:20:11 - ERROR - 🚫 INPUT BLOCKED - Secrets/PII detected!
10:20:11 - ERROR - Error: Validation failed for field with errors: The following text in your response contains PII:
Review this code:
import os
# contact codeguy@example.com with questions
if __name__ == '__main__':
print
10:20:11 - ERROR - ❌ NOT SENT to LLM (saved tokens!)
10:20:11 - ERROR - ============================================================
10:20:11 - INFO - ⚠️ Expected behavior - input blocked locally
You can see that the response has been flagged by validation and we can prevent sending to the LLM. Success!