Safe AI - Part 1
This is the first part of a series of articles about AI Safety and ways to mitigate some kinds of risks of Large Language Model (LLM) responses. The intent is to share the concept of Safe AI and techniques for solution implementors to greatly reduce risks of using AI to solve core problems. This post describes “why Safe AI” and subsequent posts will demonstrate proofs of concept.
Is AI Safe?
The short answer is, “most of the time”. Like any technology resource, AI could be manipulated to do things it wasn’t designed for. A study and industry is maturing around “Safe AI” to put guardrails in place to let AI be at its most useful while minimizing those unintended consequences.
“Safe AI” means a number of things. It refers to the behavior of and outputs from AI. Safe AI solutions are aligned to societal, organizational, and personal values. Behavior of safe AI solutions is to mitigate risks like bias, privacy violations, and misinformation. Possibly most important, safe AI solutions should mitigate unintended consequences such as personal, financial, or reputational harm.
What does a Safe AI solution look like?
There are two variations of guardrail solutions and the difference is when the guardrails are put in place. Some solutions will use both, as both have different strengths. How the model is trained is one perspective; guardrails around outputs of the LLM black box is another. We are dealing with probabilities in most of these cases, and these approaches to reduce negative outcomes have real positive impacts on those probabilities.
Some models, such as Anthropic’s, are trained to decline certain requests such as ones that involve harm, or illegal or unethical behavior. If it is not certain about a response, it will respond in a way that reflects this confidence level so the reader is less likely to be misled. When some other models hallucinate a response to a software developer that causes the dev to spend a day chasing a non-existent API, this model is more likely to let them know that it is not certain of this API. These models reduce bias, though removing human bias is almost by definition impossible. Certain kinds of bias are known to be harmful to society, organizations or individuals; these are the kinds that are reduced in model training. Finally Anthropic has pioneered the concept of Constitutional AI (link to resource at end) which trains models using a set of principles (the constitution) to critique and revise its own responses.
Other models such as OpenAI’s are trained with a different methodology. Many models use Reinforcement Learning from Human Feedback (RLHF) which allows for humans to review and compare multiple responses, choosing the best response from that person’s perspective which includes AI safety. This uses human rather than AI evaluations during training. OpenAI has also developed Deliberative Alignment, a methodology to teach models safety specifications and trains them to reason with safety considerations during inference, after training is complete.
The other kind of Safe AI solution involves putting guardrails around the inference stage. Inference can be considered the request->response lifecycle: send a request to a Large Language Model, a bunch of stuff happens, and you get a response. Organizations can wrap the beginning and end with AI prompts to validate inputs and outputs.
- Inputs don’t contain sensitive information, attempts to jailbreak, or prompt injections
- Outputs from a prompt are safe(r) from misinformation, toxic content, hallucinations, etc.
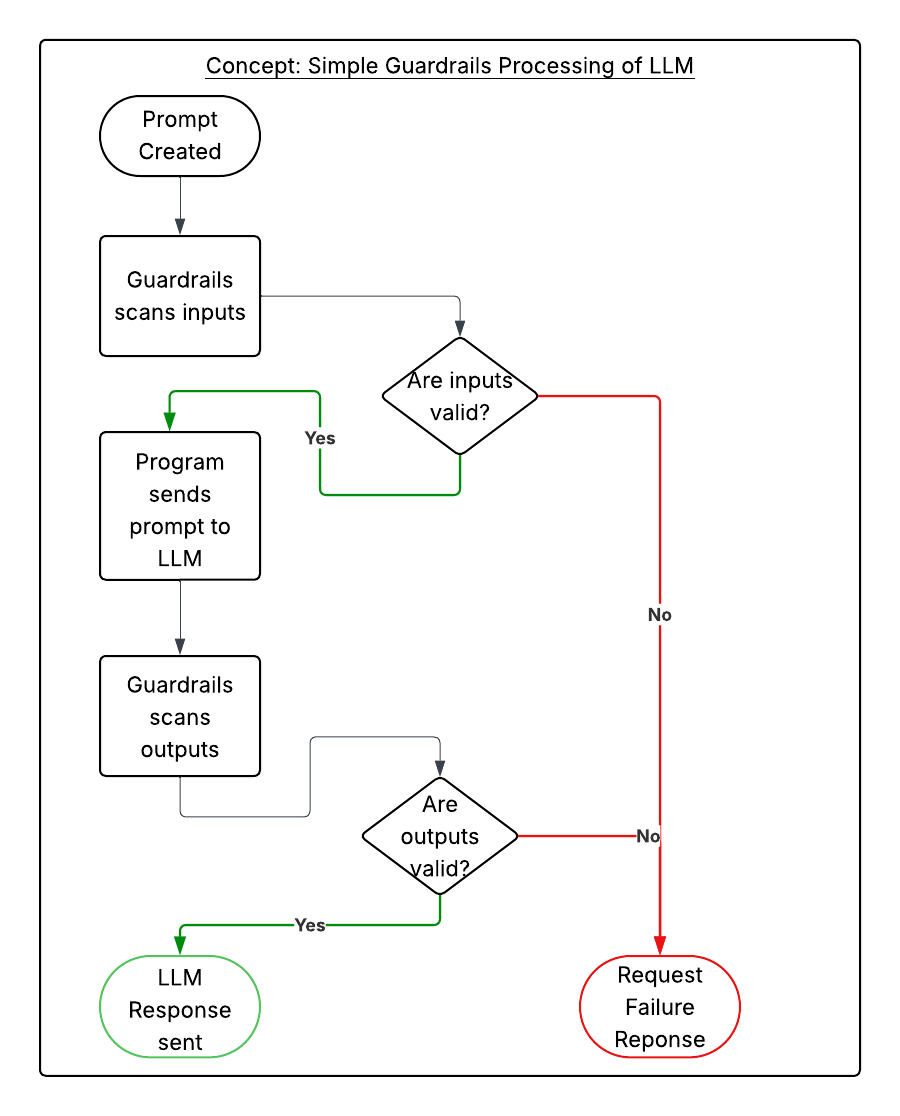
While there isn’t a perfect solution, like in many complex technology problems we can apply solutions in layers: matching models that have been trained with the Safe AI and Constitutional AI concepts in mind along with runtime governance introduces two layers that can help focus AI solutions on the intended problem domain.
What’s Next
I intend for the next posts to document a working proof of concept that leverages resources commonly available in enterprises. I am curious about and likely will write about open source Guardrails.ai tooling and popular LLMs, and possibly tools like Azure Content Safety.