Retrieval Augmented Generation (RAG) with BAML and PostgreSQL
Leverage advanced features widely available in PostgreSQL alongside the increased reliability and smarter maintenance of BAML for prompts in RAG solutions!
Here’s the situation when you want to know about this.
- You are introducing AI capabilities to your organization.
- You need a jumpstart on scaling automated prompts.
- You also need to understand capabilities of databases that are available for your use.
One approach is to use best-of-breed databases for the various uses of your project. For example, your SQL database helps with some of your project data; your NoSQL database helps with your front-end development; and you expect to need a vector database for RAG. But if you try to start with three separate servers, you risk adding too much foundational work before you can start to deliver. Introducing a new database often requires approvals and a plan to support that kind of database. This aprosch gets your project off the ground while working through those approvals, and it might even suit your needs in production.
The proof of concept documented here is an attempt to use a reliable, scalable, secure, low-cost database for all three purposes to avoid that overhead. This simplifies the landscape in the short-term and may actually serve your long-term purposes.
The full source code for this proof of concept is at https://github.com/hoopdad/rag_in_python_postgresql/
Why RAG
RAG is a solution that allows for faster, smaller interactions with a Large Language Model (LLM). It takes advantage of re-use strategies and vector math. Your AI service tracks data within a massive multi-dimensional world, and can tell you using a process called “embedding” where both your question and the relevant document information fit in that world, their coordinates so to speak. Closer items mean higher relevance. Using that vector math, you can find the closest data that pertains to that question, simplifying the prompt that you then send to the AI service for an expanded answer.
If you run many prompts against the same source, it’s worth converting your data to vectors, a process called embedding, and saving them to a database for later retrieval. If you are going to ask more than 1 question about a certain document, this is probably going to reduce your cost. By focusing the prompts on a subset of focused data, you are sending less data to your AI service and asking it to do less work, translating to fewer tokens of data exchanged and lower cost. It also means a lot less processing time for the AI service.
The scenario used in this proof of concept is asking an LLM to determine the failure cause for a workflow log file. This is the output from a series of steps. It is a mix of random bits of information about the process, results from steps within that process, and a collection of warnings and possibly errors. While it will have a single pass/fail decision at the end, more resolution on the reasons behind it, but not too much narrative, will help a team understand failures and prioritize fixes.
Note: lengthy log files often need to be consumed as a single document to provide full context. This scenario seems to work because it asks AI about any failures found; sections with anything like a failure are sent to the LLM without needing to know the entire sequential flow.
Why BAML
Previous posts in this blog about BAML covered some of the benefits of BAML, summarized here.
- A Domain Specific Language (DSL) for writing and executing prompts
- Guaranteed structured input and output for scaling agentic models and many contributors
- Separation of prompts from the framework code that runs them
- Resiliency with built-in features like retry policies
- Ability to communicate with APIs from many AI vendors, running in the cloud, on-premises, or locally
This is a key piece of a framework that allows scaling up and reusing prompts. Using the DSL lets a person focus on the prompt itself, separating system programming with prompt development.
Layers of this Solution
Database
For proof of concept purposes, I installed PostgreSQL and configured pgvector in a Docker image. See docker-compose.yml and run-db.sh
pgvector is our plug-in library for PostgreSQL that enables vector math, specifically cosine similarity, which is the math that tells how close two vectors are; closer vectors in LLMs mean relevant data in RL. It comes with some task-specific language constructs such as “<=>” which you might not see elsewhere in PostgreSQL.
See the queries in embeddings_persistence_postgres.py
Database Layer
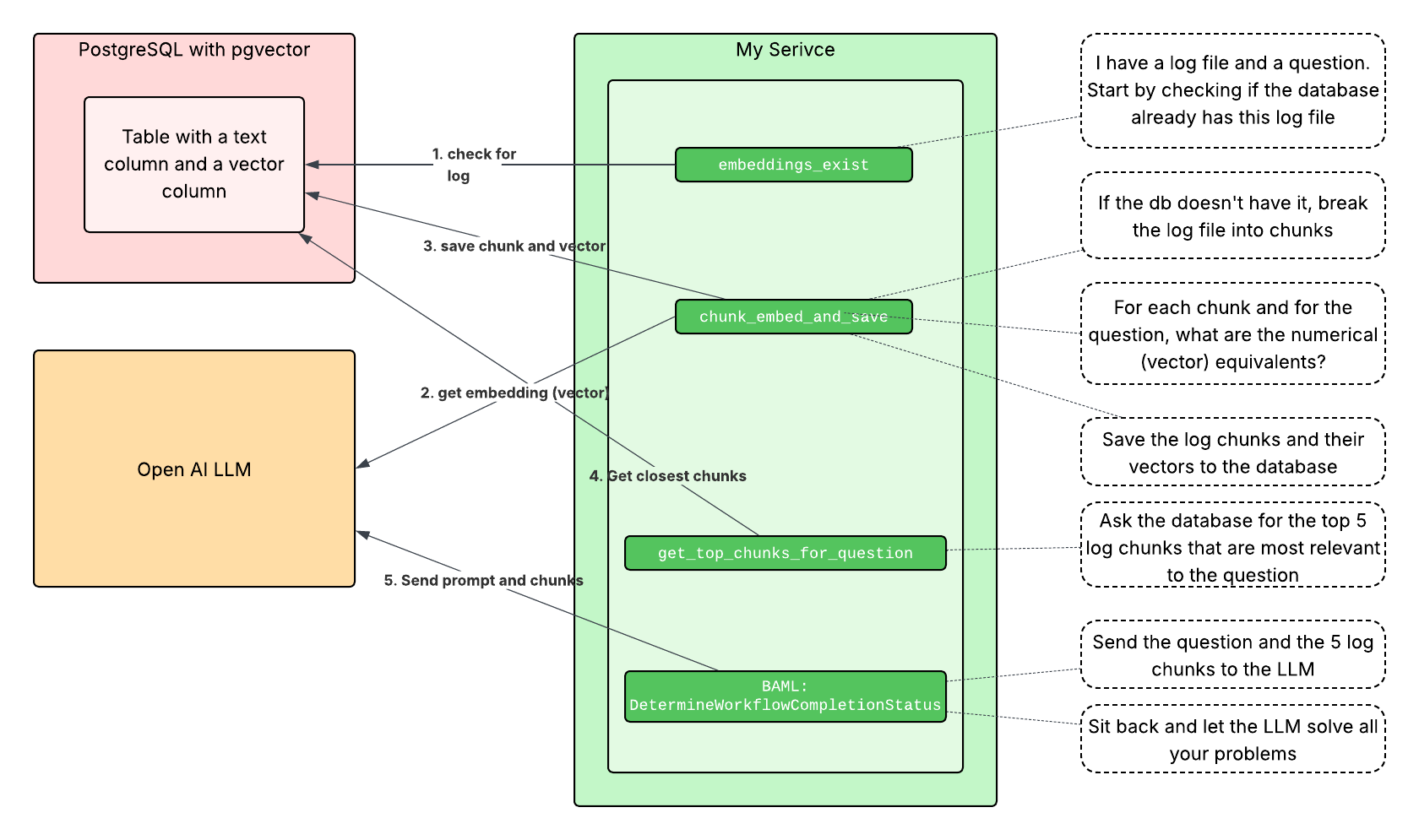
The file embeddings_persistence_postgres.py wraps our communications with our database. It includes functions as follows.
_ensure_tableis called internally and sets up our database.save_embeddingssaves the chunks of our log file to the database. Those chunks are determined by our Python code. We don’t save the whole log file as one chunk because that would defeat the efficiency gains.embeddings_existchecks if we already saved embeddings for this file. This is how we gain efficiencies in re-running prompts against the same log file.cosine_similaritysends a database query that uses our vectorized question to find the most relevant log chunks.load_embeddingswill retrieve the vectors, in cases where one might want to do the cosine similarity math on their Python client. It is not used in this POC.
Prompt Layer
This calls BAML. You can see how it’s used in the query_logs function in embed_on_postgres.py. We don’t have to write a lot of code for this!
Calling the Client
All we need to do to call the BAML client is to set up a dictionary and then pass that into our generated function. This is in query_logs in embed_on_postgres.py
prompt_input: WorkflowAnalysisDetails = WorkflowAnalysisDetails(
logs=chunks, question=question
)
response: workflow_completion_status = (
workflow_completion_client.DetermineWorkflowCompletionStatus(input=prompt_input)
)
Defining the prompt
Check out workflow_completion.baml to see how we define our prompt.
Then see how we define the connection to our AI Service in clients.baml. Note the use of an Azure Open AI service, my Open AI instance that is hosted on Azure, along with the retry policy. Retry is so important in cloud design that it is built into the BAML framework.
Once we edit the baml files, we run baml-cli generate to generate our python code.
Define our input model. By using the BAML library, the type definition used by BAML is approximately 1/4 the size of a JSON schema we might otherwise use, saving more tokens. Additionally the description is used to comment your code while defining the field for the LLM. You can see a similar definition for the output in workflow_completion.baml.
class WorkflowAnalysisDetails {
logs string[] @description(#"
Chunks of logs deemed by a vector proximity to be relevant to the question
"#)
question string @description(#"
The key analysis question to consider when reviewing these log chunks
"#)
}
Define our prompt.
function DetermineWorkflowCompletionStatus(input: WorkflowAnalysisDetails) -> WorkflowCompletionStatus {
client "Azure_openai"
prompt #"
You are a helpful DevOps engineer with expertise in Terraform, AWS and GitHub Actions.
Use the following log context to answer the question.
Question:
{{input.question}}
Context:
{% for logChunk in input.logs %}
----
LOG CHUNK
{{ logChunk }}
----
{% endfor %}
{{ ctx.output_format \}}
"#
}
Notice how this is very focused just on the prompt. If the prompt changes, this file changes and not your other source code, decreasing code brittleness.
Putting it all together
These are the steps that we handled in this proof of concept.
- Create our database instance, running in our local Docker
- Create our table if it doesn’t exist
- Check for our log file in our RAG database
- If it’s not already there, break it into chunks, vectorize (“embed”) each chunk, and save all of that to the database
- Embed our question
- Ask the database to give us the log chunks most relevant to the question
- Send the question and log chunks through BAML to the LLM
- Output our response
Conclusion
This proof of concept proof of concept successfully achieved several key goals.
It proved that PostgreSQL has a competent engine for doing advanced AI work, RAG. This is a versatile, low-cost database that can be run in any cloud, in a data center, or on your laptop.
It proved that BAML can remain not just a player in single prompts, in multi-prompt chaining, and agentic models, but also in RAG. It features a for loop that makes including lists of document chunks, for one, but we covered many other benefits as well.
It also proved that RAG can be implemented quickly without too many moving parts.
There are certainly opportunities to improve on the scalability and resiliency of this RAG proof of concept. For example, document and model versions and dates could be included as metadata that would enhance the relevance of pre-saved embeddings. Line numbers for document chunks could be included for easier reference. And actually it should be developed as a service that can run on a server somewhere, not under my desk. Most importantly, however, this is a great foundation to iterate on.