File Loading with AWS and Snowflake
This follows a hypothetical use case of creating a CSV file locally, then using Amazon S3 to stage the file for Snowflake, finally importing it into Snowflake.
Benefits of the Approach
- By creating the S3 bucket and related constructs in Snowflake, it sets up easier future loads. Each time there is a new file, you don’t have to re-do the whole stack.
- By using the Snowflake Stage, you are moving the file close to the target, to see a reduction of the risk of network errors like timeouts or overall slowness from network latency.
The AWS Non-Human User
This is a reusable Non Human Account - your company surely has policies governing use of these.
- In AWS IAM, create a user for non-console access.
- Under Security Credentials, find access keys and click “Create access key” to generate.
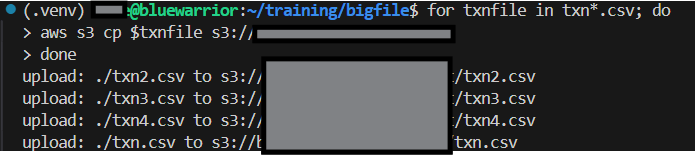
Copy your file to your s3 bucket
The local work is shown here in a Windows Subsystem for Linux (WSL) console in Windows 11.
- Install aws cli
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/install
- Configure AWS CLI by running
aws configure; specify the credentials from the first IAM step. - Create an s3 bucket in AWS
- Set RBAC or policies to allow s3:ListBucket, s3:GetObject, s3:PutObject on your new bucket for the user above.
- Copy the file to s3
aws s3 cp <local-csv-file> s3://<bucket-name>/<csv-file>
For my test, I wrote a python program to generate random data in several files with 10,000 rows each.
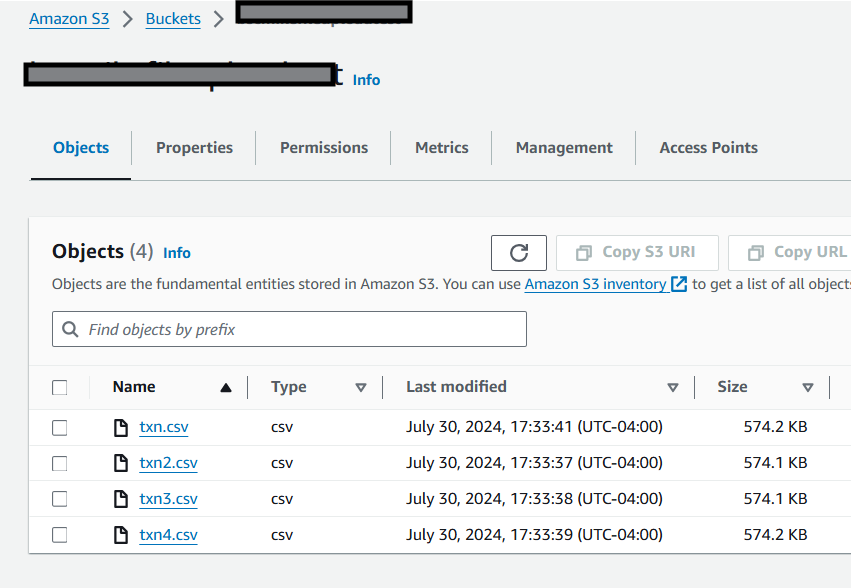
This is the familiar s3 interace showing the successful uploads.
Install snowsql
I installed it to ~/bin. My config file after install is at ~/.snowsql/config.
curl -O https://sfc-repo.snowflakecomputing.com/snowsql/bootstrap/1.3/linux_x86_64/snowsql-1.3.1-linux_x86_64.bash
bash snowsql-1.3.1-linux_x86_64.bash
Configure snowsql
- set file permissions on the config file
chmod 700 ~/.snowsql/config
- open ~/.snowsql/config i.e.
code ~/.snowsql/configorvi ~/.snowsql/config - find the config.example section. Later, we will use the key word “example” from that section in our command line. If you don’t like “example”, name it how you would like here and later in the snowsql login.
- set account = to the account value which is like “abc12345.us-east-1”. I logged into the Snowflake UI and ran a workbook with
SHOW CURRENT_ACCOUNT(); - Set username and password values.
- Use quotes around all the values, i.e.
username = "thisuserid"
Connect to your database in snowsql
I show the settings where I want detailed log info in case login fails and I use an MFA passcode. You have to update the string for the mfe passcode every login, from the authenticator on your phone, assuming you have MFA set up like I do.
~/bin/snowsql -c example -o log_level=DEBUG --mfa-passcode <get-it-from-mfa-app>
Create an Internal Stage
An internal stage gives you a filesystem-like object to work with in the Snowflake SQL language, with storage local to the Snowflake Warehouse.
use database FIN_TXN;
use schema STOCK_TRADES;
CREATE OR REPLACE STAGE STOCK_TRADES_STAGE;
Create an External Stage
This gives you the construct to easily connect to an S3 bucket in the same language you use on an internal stage. Named external stages are optional, but recommended when you plan to load data regularly from the same location.
Use credentials from the AWS IAM step.
use database FIN_TXN;
use schema STOCK_TRADES;
CREATE OR REPLACE STAGE THIRD_PARTY_TRADES_STAGE
URL='s3://<bucket-name>/'
CREDENTIALS=(AWS_KEY_ID='<aws_key_id>' AWS_SECRET_KEY='<aws_secret_key>');
You can now browse your databases in the Snowflake web UI to see all of these created. Here’s what mine looked like.
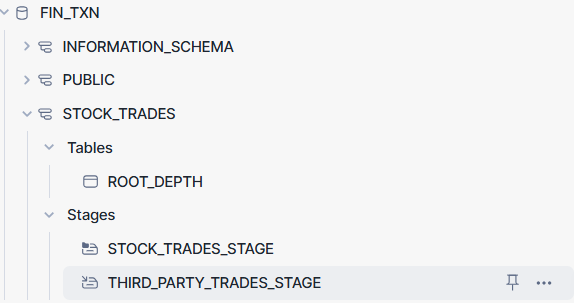
Loading Files
You now have all the structures in place. Here’s what mine looked like.
Directly Load from S3
COPY INTO FIN_TXN.STOCK_TRADES.ROOT_DEPTH
FROM @THIRD_PARTY_TRADES_STAGE/<csv-file>
FILE_FORMAT = (TYPE = 'CSV', skip_header=1);
Copy the file to your stage from the external stage
COPY files into @STOCK_TRADES_STAGE
FROM @THIRD_PARTY_TRADES_STAGE/<csv-file>;
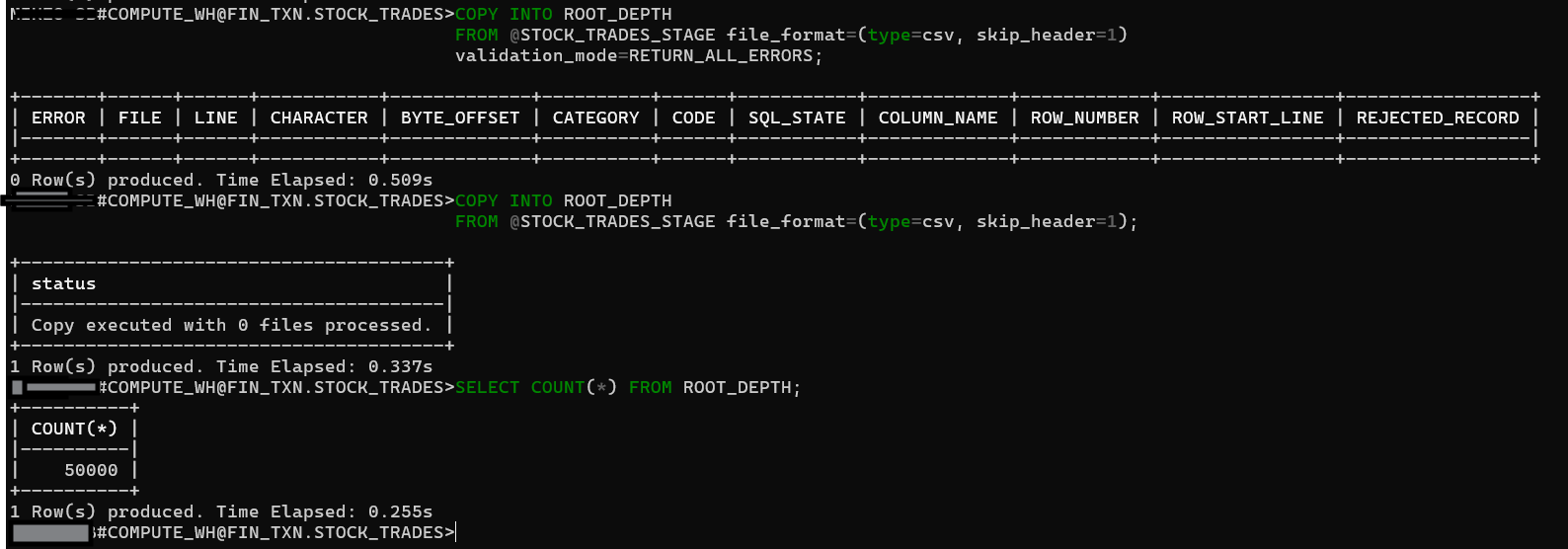
Validate the file in Stage
COPY INTO ROOT_DEPTH
FROM @STOCK_TRADES_STAGE file_format=(type=csv, skip_header=1)
validation_mode=RETURN_ALL_ERRORS;
Load your table
COPY INTO ROOT_DEPTH
FROM @STOCK_TRADES_STAGE file_format=(type=csv, skip_header=1);
Conclusion
You now have 50,000 records in your table, thanks to the 40,000 we just added.
Notice how fast Snowflake (in a Snowflake-AWS subscription) is processing 10,000 records at a shot, once in the S3 bucket. Real workloads may includes millions of rows, but this gives you an idea of how quickly this system can process data.

